 Image credit: Unsplash
Image credit: UnsplashAbstract
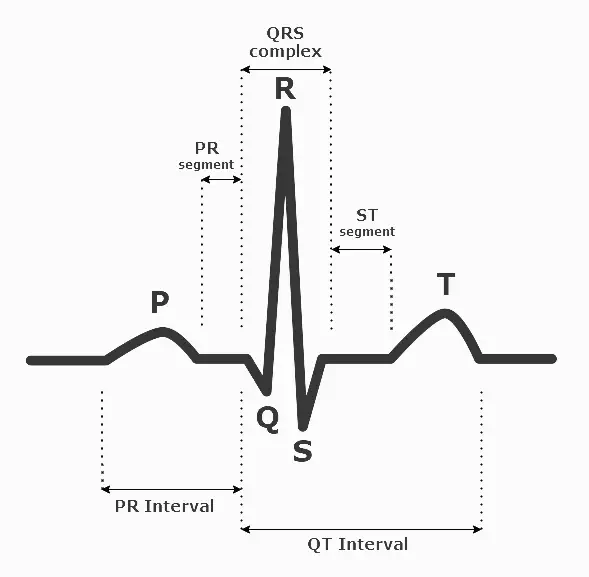
This paper studies and compares several different ways of classifying time series data using machine learning instead of popular deep learning models that need large amounts of data and high computational requirements to train. The models are compared over the MIT-BIH Arrhythmia database, which contains electrocardiogram (ECG) signal data used to monitor a patient’s heartbeat, and classifies the data into different types of diseases. The various methods explored to classify this data are Time Series Forests (TSF), Random Interval Spectral Ensemble (RISE), Word extraction for time series classification (WEASEL), and K-Nearest Neighbours with Dynamic Time Warping (DTW). The models are then compared on the basis of the amount of data needed to train, accuracy, precision, recall, time to train, and time to predict per sample. This research aims to compare the performance of these unconventional dictionaries, frequency, and intervalbased time series classification models and identify the fastest and most robust algorithm. Time Series Forests emerge to be the fastest ML-based time series classifier, making it suitable for many potential smart devices which desire to perform on-device time series classification.
Niraj Yagnik
Head of Machine Learning
Passionate about AI, software engineering, and product development, with a focus on leveraging technology to democratize accessibility and create impactful solutions.