 Image credit: Unsplash
Image credit: UnsplashAbstract
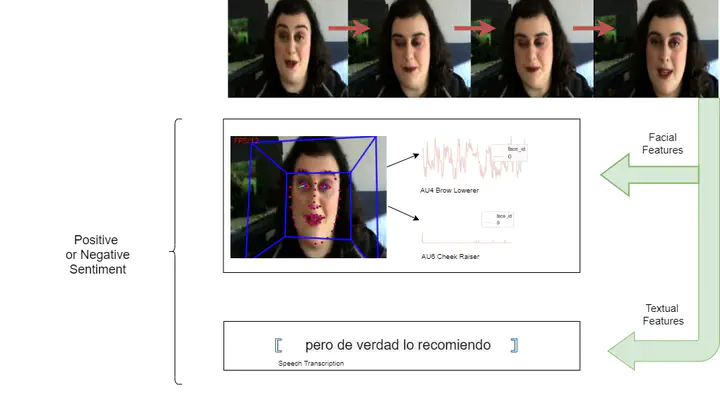
Human communication is not limited to verbal speech but is infinitely more complex, involving many non-verbal cues such as facial emotions and body language. This paper aims to quantitatively show the impact of non-verbal cues, with primary focus on facial emotions, on the results of multi-modal sentiment analysis. The paper works with a dataset of Spanish video reviews. The audio is available as Spanish text and is translated to English while visual features are extracted from the videos. Multiple classification models are made to analyze the sentiments at each modal stage i.e. for the Spanish and English textual datasets as well as the datasets obtained upon coalescing the English and Spanish textual data with the corresponding visual cues. The results show that the analysis of Spanish textual features combined with the visual features outperforms its English counterpart with the highest accuracy difference, thereby indicating an inherent correlation between the Spanish visual cues and Spanish text which is lost upon translation to English text.
Supplementary notes can be added here, including code, math, and images.
Niraj Yagnik
Head of Machine Learning
Passionate about AI, software engineering, and product development, with a focus on leveraging technology to democratize accessibility and create impactful solutions.