 Image credit: Unsplash
Image credit: UnsplashAbstract
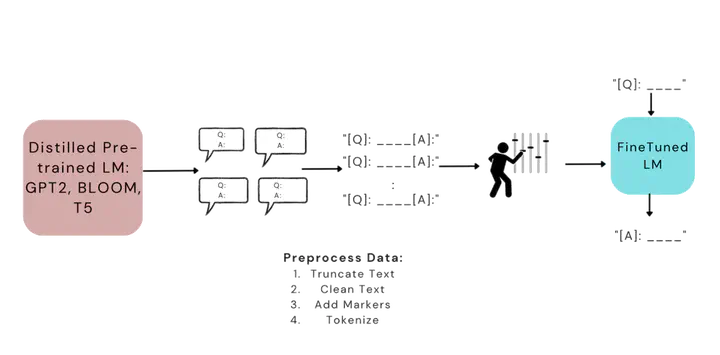
In the face of rapidly expanding online medical literature, automated systems for aggregating and summarizing information are becoming increasingly crucial for healthcare professionals and patients. Large Language Models (LLMs), with their advanced generative capabilities, have shown promise in various NLP tasks, and their potential in the healthcare domain, particularly for Closed-Book Generative QnA, is significant. However, the performance of these models in domain-specific tasks such as medical Q&A remains largely unexplored. This study aims to fill this gap by comparing the performance of general and medical-specific distilled LMs for medical Q&A. We aim to evaluate the effectiveness of fine-tuning domain-specific LMs and compare the performance of different families of Language Models.